这几天在使用llama.cpp遇到了一个坑,查阅了网上基本没啥资料提过,最后通过ollama部署的qwen3.6才有进展并解决。
坑点
就是在上篇中下载使用了在github中发布的cuda版本,于是就愉快地运行了,以为部署就完成了,毕竟运行结果测试都是正常的。直到在部署 hermes 时问题来了,在配置hermes model时一直出现503的错误,配置了飞书也是一直提示超时重试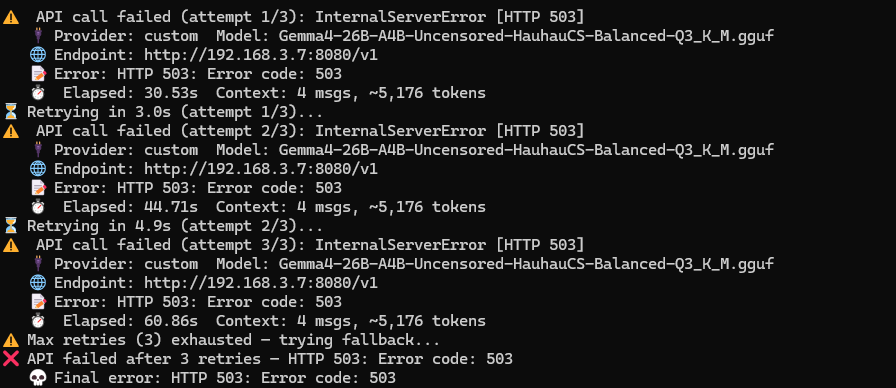
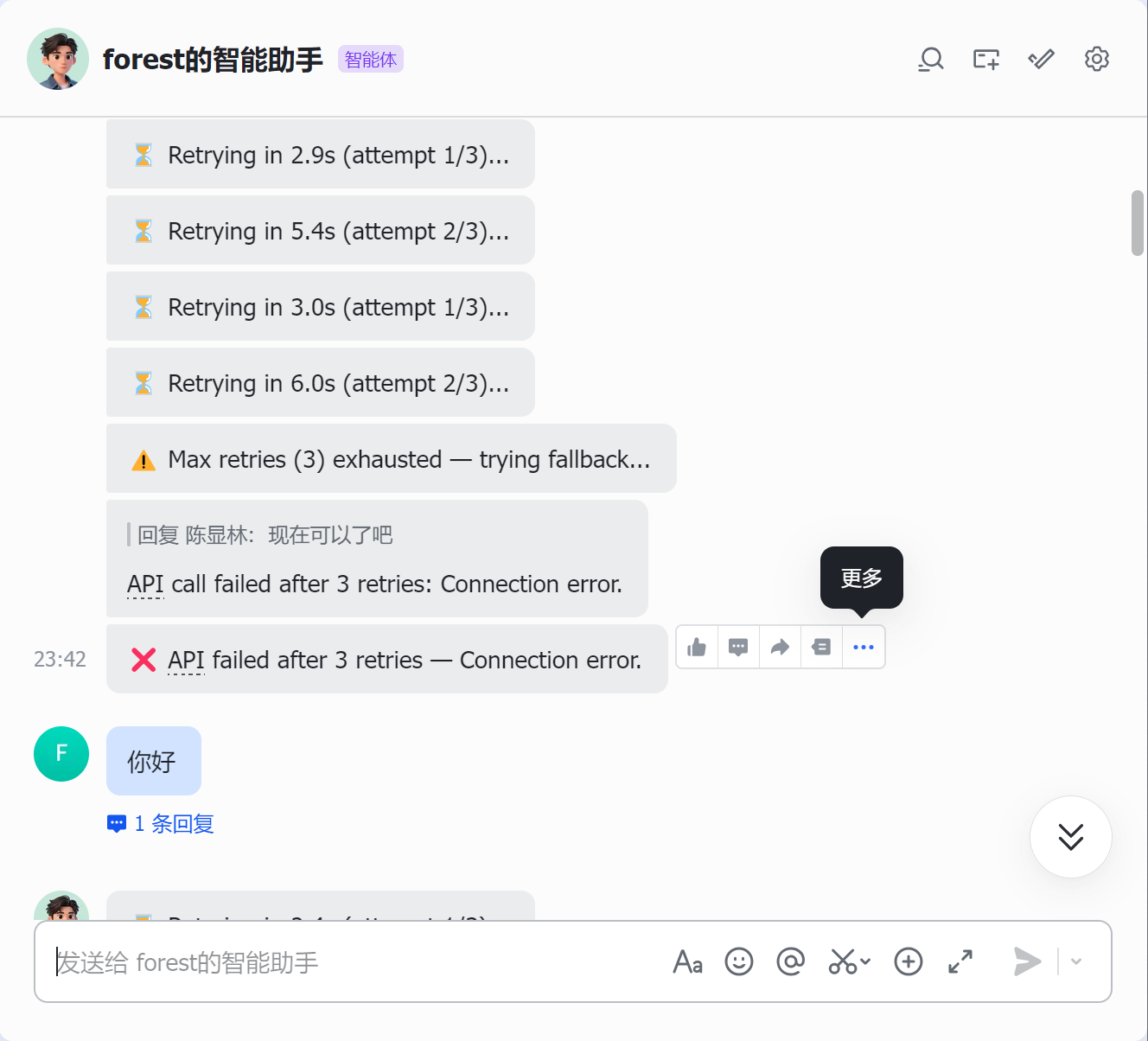 查过了各种诸如用户权限,网络代理,模型大小等常见问题依旧不得其解。
查过了各种诸如用户权限,网络代理,模型大小等常见问题依旧不得其解。
原因
llama.cpp一直用的是cpu与内存在推理
当我使用llama.cpp自带的webui时虽然能正常回答,但是速度也是不快,查看电脑性能指标时发现只有CPU跟内存上升,GPU浮动不大,1两个点,在查了llama.cpp相关启动参数之后说加-ngl 99就是用的GPU推理了,显然我一直都在用,结果就是没用上GPU,最终在与qwen3.6的对话中一步一步引导我确认了如何才能正确使用GPU部署的前提:不单单通过 nvidia-smi 命令确认驱动安装好,还要通过 nvcc -V 命令确认cuda运行环境。而我明显就是 cuda runtime 环境缺失了...
解决
下载安装 cuda 运行时库:https://developer.download.nvidia.com/compute/cuda/13.3.0/local_installers/cuda_13.3.0_windows.exe
安装后再重新打开输入nvcc命令查看是否完成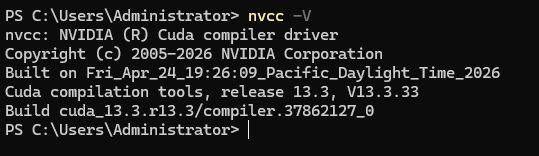
此时再运行 llama.cpp 才是真正地走了 GPU,看运行日志中的 device_info 就能看出来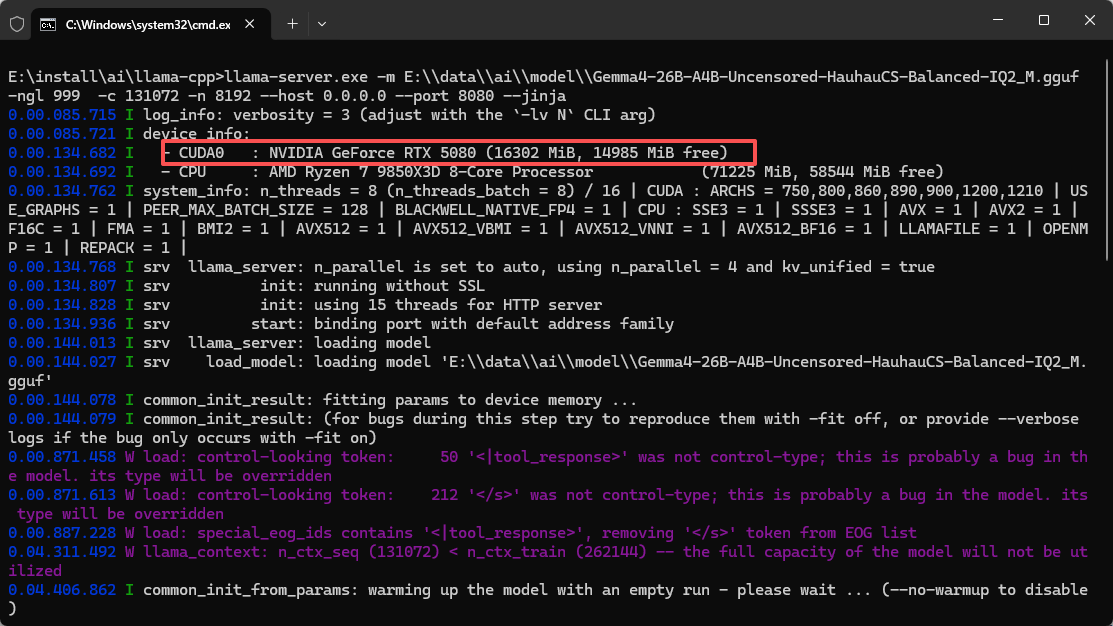
此时你再用 hermes 问一下 “中国朝代一览表”,GPU就开始工作了,而且这速度才让整个世界都舒适了~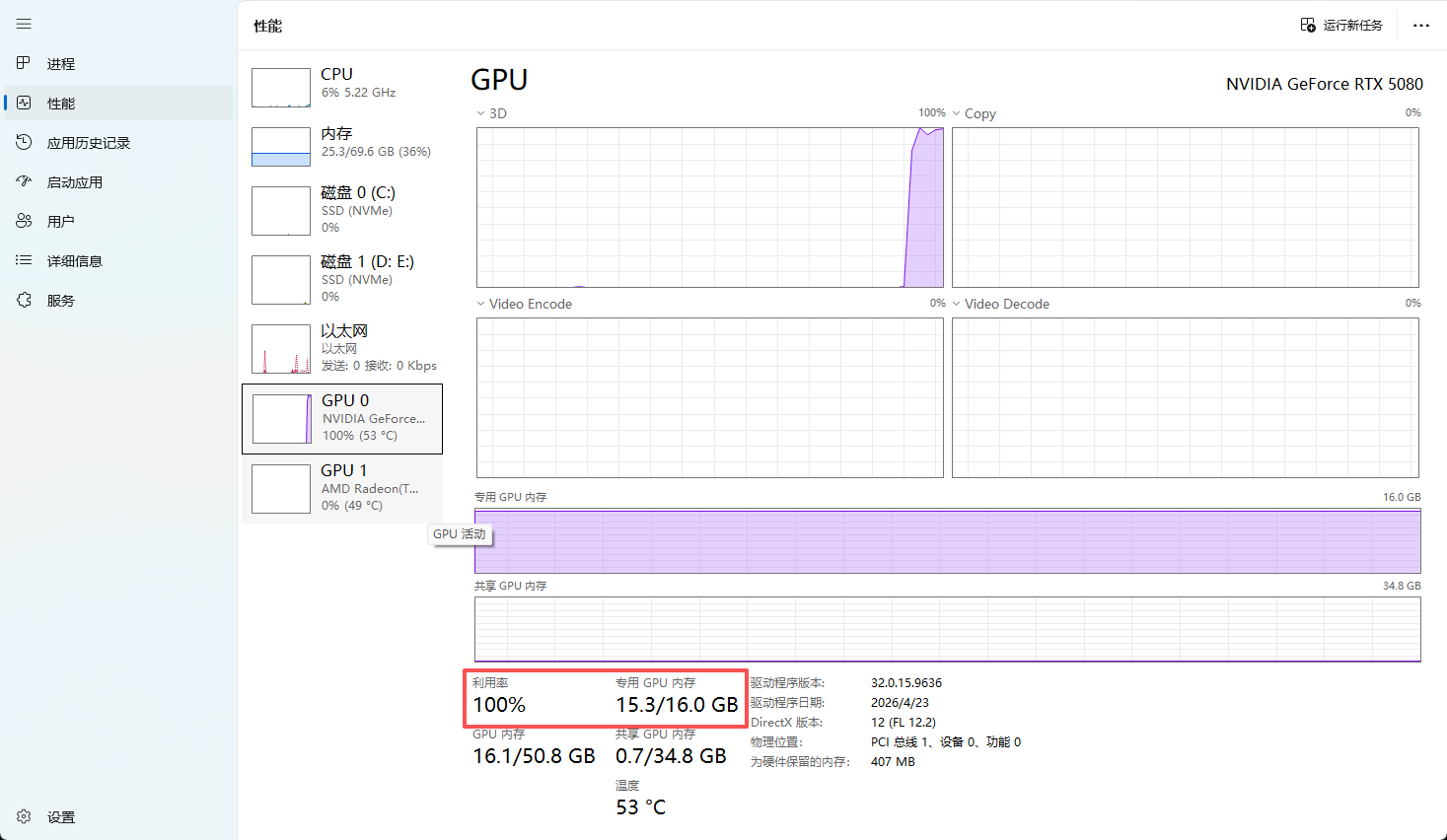
再继续看看飞书是否正常